Survival analysis of hard disk drive failure data.
Ross Lazarus, February 2016
Executive Summary:
Using a well established, objective analysis and data presentation method designed for right censored hard disk drive failure data provides insights which are not provided by simple descriptive statistics or charts. The Kaplan-Meier statistics and plots are recommended for routine use with hard drive failure data and their use is illustrated with 30M data points from the BackBlaze public data.
Introduction:
Subjective experience of individual consumers who purchase a few drives at a time is readily available in on-line product reviews at the larger retailers like Newegg or Amazon. These reviews are likely to be biased by negative reviews from those unlucky owners of a drive which happened to fail quickly - satisfied owners are less likely to take the time to share their experiences compared to unhappy owners who have just lost precious data.
Large commercial purchasers such as Google or Amazon probably do their own in-house testing, but rarely share their hard won findings or raw data. As drive capacities grow, new models are released on a regular basis but it takes at least 2 or 3 years of observation of a large number of sample drives under typical field operation conditions before robust conclusions can be drawn on the reliability over time for each new model.
The most recent analysis of about 50,000 hard disks deployed in a commercial on line storage facility over nearly 3 years run by Backblaze is one of the largest published studies and can be viewed at https://www.backblaze.com/blog/hard-drive-reliability-q3-2015/ and in other Backblaze blogs. Simple statistics, tables and bar graphs derived from 30,301,566 observations are presented and discussed. That's a lot of data and the Backblaze engineers have done their best to make sense of it. Unfortunately I'm not sure that you can really see what's going on from their presentation. For example, time is split into 3 year-long intervals in the main table, making it confusing and hard to figure out what's really going on, and the summary bar charts hide an awful lot of interesting detail.
Failure time (or survival) analysis:
Part of the challenge in interpreting this type of data is the problem that at any point in time during the observation period, one or more drives (or patients or more generally, units of analysis) may fail, and one or more drives may be removed from any further study before failure because of firmware diagnostics or planned maintenance. In terms of statistical analysis, this problem is termed right censoring because no further information is available after a drive is removed. Right censoring must be taken into account in order to correctly calculate the instantaneous failure rate of drives in the context of drives removed from further observation at some point before they failed together with the remaining drives which have not failed (yet).
Epidemiologists and statisticians have established valid and robust methods for handling right censored data in the context of survival analysis, which are applicable to the Backblaze data. Survival rates are the inverse of failure rates, so survival and failure analysis are more or less mathematically equivalent, being two sides of the same technical coin although failure time analysis predominates in engineering circles whereas the survival analysis paradigm predominates in biology.
One popular method is the Kaplan-Meier (KM) plot and KM statistics, widely used to compare (for example) survival time after diagnosis for patients with the same cancer but different treatments. This kind of data is similar to the hard drive failure data because the reality is that it is almost inevitable that some patients in any clinical study will be lost to further follow up after a visit at which they were clearly alive. Those right censored patients, like the drives removed before failure, contribute no more information to the study, but do contribute useful information for the whole time they are being observed. Some details on where the data came from and how the analysis was performed are provided at the end of this article.
Application of survival analysis to hard disk drive failure data:
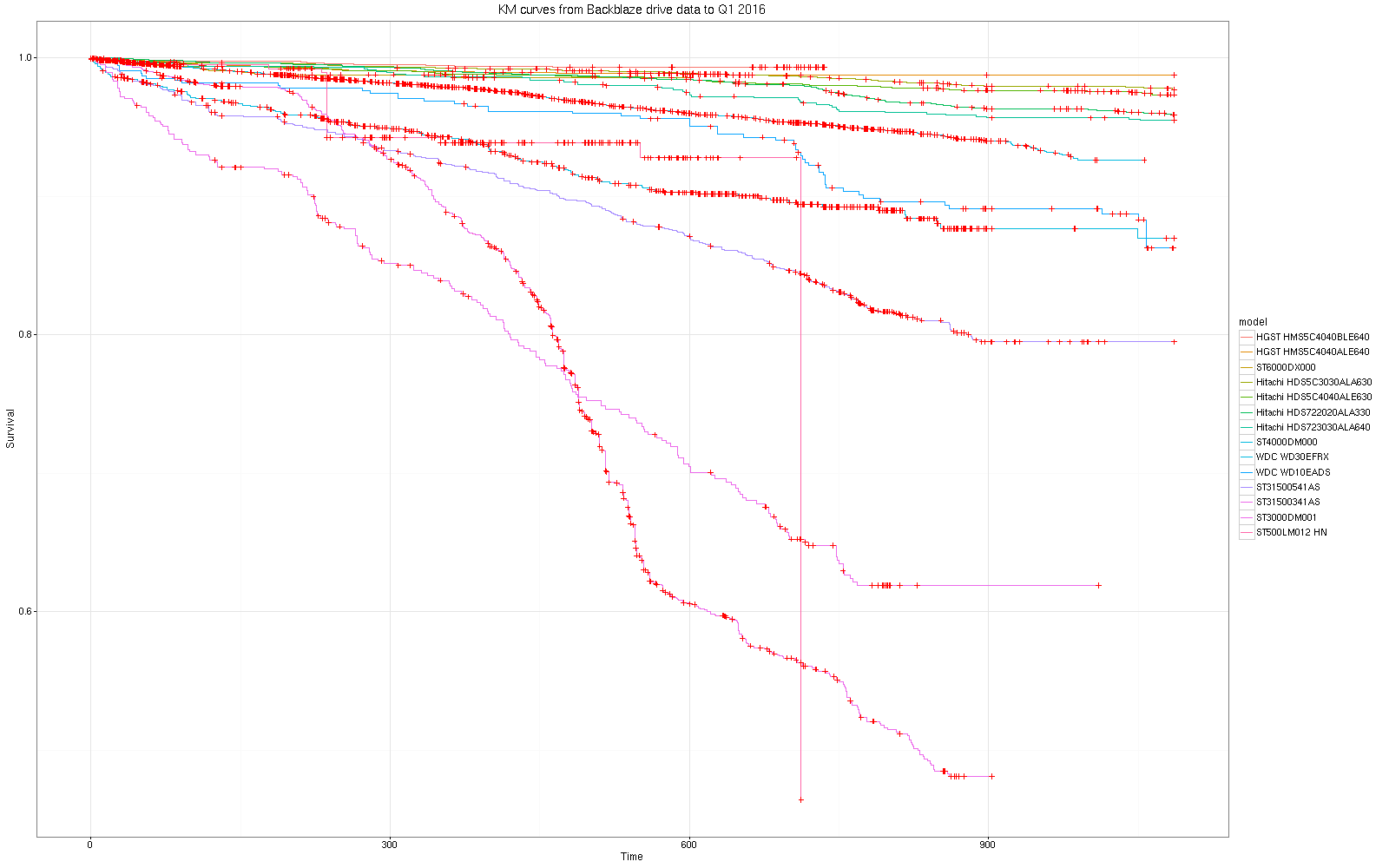
Here's a KM plot showing the survival of each drive by the manufacturer.

The vertical axis represents the fraction of drives which survived at any given point in time and the horizontal axis represents days since time zero. Each individual disk drive's history over time is "lined up" so the first day of observation is always at the far left, at time zero - like a race where each competitor starts at the same point, although in the raw data, drives were introduced to the pool continuously over the entire study period. Each manufacturer's drives are grouped together and their survival in service over time is plotted as a single line. When one or more drives fail, there is a small vertical step in the curve. Each cross on each line represents a right censored observation removed from further study. Note that right censoring has no effect on the instantaneous survival rate - it simply changes the denominator for failure or conversely, survival rate calculations. Each downward step in each line represents one or more failures at that time.
Here is the Backblaze summary chart linked from their report at https://www.backblaze.com/blog/hard-drive-reliability-q3-2015/
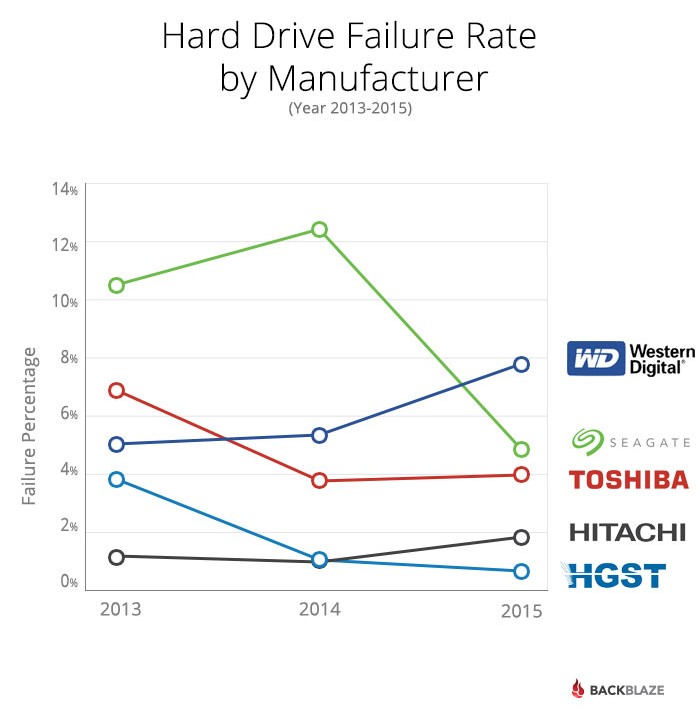
To my eye, the KM curve provides a much more detailed and arguably more accurate summary of what happened during the observation period. Note the curve for ST500LM012 which is an obvious anomaly arising from an abberant manufacturer string in the data ("ST500LM012 HN") where the two space delimited components in the data field are reversed (see below) compared to the majority of the data where the model follows the manufacturer abbreviation. This does not seem to have been noticed in the Backblaze analysis but the KM plot makes it obvious. No attempt has been made to correct this anomaly because it is not clear whether the model number means that the "HN" is wrong and should be replaced by "ST" - I'll leave that for the BackBlaze engineers to figure out and fix!
One example of a feature that was not at all obvious from the Backblaze analysis, but is clear from the KM plot, is the crossover in failure rate between ST (Seagate) and WDC (Western Digital). Initially, the WDC family failed slightly faster but the Seagate family of samples failed more quickly after about the first year of operation.
The KM statistical test estimates expected failure rates from mean failure rates and the number of units under observation at each time point and as shown below, suggests that drive survival is significantly different between manufacturers with some (eg HGST) having far fewer observed failures than expected and others (eg ST) having far more than expected, with a global Chisquared value of 2535 which is extremely unlikely to have arisen by chance alone :
N Observed Expected (O-E)^2/E (O-E)^2/V
manufact=HGST 10424 100 515.21 3.35e+02 4.08e+02
manufact=Hitachi 13244 385 1533.11 8.60e+02 1.53e+03
manufact=ST 32714 3266 1798.14 1.20e+03 2.21e+03
manufact=ST500LM012 377 22 8.89 1.93e+01 1.94e+01
manufact=TOSHIBA 254 9 9.15 2.59e-03 2.59e-03
manufact=WDC 3753 298 215.49 3.16e+01 3.34e+01
Chisq= 2535 on 5 degrees of freedom, p= 0
The KM plot pattern seems much easier to understand and at all obvious from the table or bar graphs shown in the original article.
For individual drive models, the KM curves are complex but even more revealing:

The KM curves show that one particular Seagate model failed at an unusually high rate over the entire period, whereas the curves at the top of the plot show a group of very reliable drive models which had very few failures over the entire period of observation. These individual drive model curves are made from the same data as the manufacturer curves but reveal a great deal of interesting variation within each manufacturer's offerings - again suggesting that descriptive and summary statistics presented in the Backblaze blogs hide a lot of important and interesting complexity.For individual drive models, the KM curves are complex but even more revealing:
Again, the KM statistics show that the differences between models seen in the KM plot are statistically significant and unlikely to have arisen by chance alone.
N Observed Expected (O-E)^2/E (O-E)^2/V
model=HGST HMS5C4040ALE640 7168 73 285.7 1.58e+02 1.83e+02
model=HGST HMS5C4040BLE640 3115 21 194.6 1.55e+02 1.67e+02
model=Hitachi HDS5C3030ALA630 4662 98 519.4 3.42e+02 4.09e+02
model=Hitachi HDS5C4040ALE630 2719 63 298.9 1.86e+02 2.05e+02
model=Hitachi HDS722020ALA330 4774 175 530.7 2.38e+02 2.86e+02
model=Hitachi HDS723030ALA640 1048 45 115.3 4.29e+01 4.45e+01
model=ST3000DM001 4707 1705 305.5 6.41e+03 7.06e+03
model=ST31500341AS 787 216 45.1 6.47e+02 6.55e+02
model=ST31500541AS 2188 392 199.1 1.87e+02 1.98e+02
model=ST4000DM000 21671 695 1025.8 1.07e+02 1.52e+02
model=ST6000DX000 1906 26 27.6 9.20e-02 9.51e-02
model=WDC WD10EADS 550 53 54.7 5.38e-02 5.47e-02
model=WDC WD30EFRX 1267 114 73.6 2.22e+01 2.27e+01
Chisq= 8587 on 12 degrees of freedom, p= 0
More complex models:
The KM plot is a robust, non-parametric method which is attractive because of the lack of assumptions about the data. More sophisticated methods such as Cox proportional hazards models require distributional or other assumptions, but allow adjustment for additional variables such as the kind of storage pod (see the Backblaze blogs), drive capacity, number of platters or other factors of interest. My view is that this is not going to be at all useful until a lot more data becomes available.
Conclusions:
Other than as a consumer, I don't have any particular expertise on hard disk drives but I have made a successful career out of interpreting large scale data sets using appropriate statistical methods. I find the KM analysis much more clear and easy to interpret compared to the simple descriptive statistics presented by Backblaze and I hope they use more appropriate methods going forward. I'm happy to help if anyone cares to ask.
Technical details and data source:
The Backblaze folk have done a great service to the community by making their data freely available for anyone willing to poke at it at https://www.backblaze.com/hard-drive-test-data.html.The data release which includes the third quarter of 2015 was downloaded in early February 2016 and is reported here.Here's a small sample of the 30,301,566 rows of raw data available from Backblaze. There's a separate CSV format file for each day of each year. These are stored under three year (eg 2013) directories. This is from the start of "2013/2013-04-10.csv"
| date | serial_number | model | capacity_bytes | failure |
| 2013-04-10 | MJ0351YNG9Z0XA | Hitachi HDS5C3030ALA630 | 3000592982016 | 0 |
| 2013-04-10 | MJ0351YNG9WJSA | Hitachi HDS5C3030ALA630 | 3000592982016 | 0 |
| 2013-04-10 | MJ0351YNG9Z7LA | Hitachi HDS5C3030ALA630 | 3000592982016 | 0 |
| 2013-04-10 | MJ0351YNGAD37A | Hitachi HDS5C3030ALA630 | 3000592982016 | 0 |
Since I don't trust the smartdrive stats, I threw all those columns away and split out the manufacturer code and model from the "model" field.
The Kaplan-Meier plot and test statistics are available in most worthwhile statistical packages and I used the npsurv function from the R survival package for the plots and statistics reported here. In order to improve the reliability of the model curves, drives with fewer than 500 observations were dropped.
A python script was used to read all the files, keeping track of the appearance and disappearance of each unique drive as defined by a combination of model and serial_number, while processing each day's data in sequence. No database needed - python easily handles this data as an in memory dictionary, after dropping all the smartdrive columns. After reading all 30 million rows, a summary file containing a single row for each unique drive with the date it first appeared, the number of days it was under observation and a code indicating whether it failed or not was written. That script processed about 30,000 csv rows a second on my oldish desktop taking about 17 minutes for the entire dataset. The R script takes only a few seconds to perform the KM analysis and generate plots.

I'm interested in this phrase:
ReplyDelete"Since I don't trust the smartdrive stats, I threw all those columns away"
Why not? Is there good statistical basis not to trust them? I generally find the uncorrectable error rates and realloc sectors to be good (if fuzzy) indicators of failure, but most of my data points are based on the spectacularly unreliable Seagate Barracudas.
Thanks for the comment.
ReplyDeleteThree reasons why the smartdrive stats are not used here:
1) I'm not smart enough to understand how they can be used to provide useful insight into this data
2) I wanted the simplest models that provide interesting insight. Cox and other models incorporating continuous covariates are much harder to interpret
3) I read some discouraging comments about the smartdrive stats in some of the backblaze data blogs.
4) The smartdrive stats have far too much missing for me to trust them or to want to fool around with imputation to make KM or Cox models possible.
Please feel free to share your own findings if they help make the data easier to understand.
Thank you for providing this analysis. I find the legends for the plot very hard to use. I think the usability of this information could be improved by adding a label on each of the lines.
ReplyDeleteI also found the legend very difficult to read, and the colours too similar. I've just discovered your interesting post due to going through another research/buying cycle for a couple of new drives.
DeleteThere's a legend which works for me but please feel free to send me a pull request to improve the plots so they'er labelled the way you prefer. Source at https://github.com/fubar2/backblazeKM
ReplyDeleteGGally::ggsurv can add texts along the curves, which would be more readable for large plots IMHO. Thanks for your analysis.
DeleteThank you for this interesting insight!
ReplyDeleteI fully agree that your analysis is much easier to interpret and reveals more detail than the original analysis done by Backblaze. I have never used or seen KM-plots but it seems to be a very handy tool.
Thanks again and thumbs up.
For Nathan and other people like me who strangle to distinguish the colours in the models plot: https://dl.dropboxusercontent.com/u/242368/km_model_feb2015_rl.png (I only spent time on the top survivors)
ReplyDeleteDid you see the updates at http://bioinformare.blogspot.com.au/2016/05/survival-analysis-of-hard-disk-drive.html ? I reran the scripts with the Q1 2016 data added. More data = more reliable estimates.
DeleteOh! and thanks for your effort and mostly the fine idea of using KM-plots for such cases Lazarus. Vastly better than the simple statistics we usually see.
ReplyDeleteExamining the nations of the brands is interesting. The Japanese brands perform better than the USA brands. So WD bought HGST, the best performer. HGST is now totally owned in every way now by WD, so will the worst performer now and the best performer move towards the mean?
ReplyDeleteOutsiders like myself are wondering if and when South Korea and Chin will enter these charts. Unfortunately these charts do not cover the nations of manufacture of the products, ... yet.
Ownership and brand-origin of the brands seem to show patterns in the above charts. I am guessing that all items are made in factories based in East Asia, including Thailand, Singapore, Vietnam & China? Perhaps the nation of final assembly of the metal units might show interesting patterns?
In the developed nations like Australia (where we live now), USA, etc have lost most of our factory creativity. Will East Asia be able to better our abilities?
Although WD bought HGST they did not get the 3.5" technology which was bought by Toshiba.
DeleteHGST was a combination of Hitachi and IBM technology.
Innovators are usually the American companies and then the superior manufacturing of the Japanese refines that technology until it is taken over by the Chinese manufacturing giants.
Interesting analogies can be seen in all industry sectors but just look at the histories of the Transistor radio, TVs, Video player/recorders etc,
I can say as an end user I agree more with these graphical representations then backblaze, seagates are absolute garbage, lost everything I had
ReplyDeleteSMART was done to hide data rather than make it public. In the old days, when you bought drives they came with a defect list which you manually added into a bad sector table. Drive manufactures realized having a list of how many bad spots were on their products was not a good marketing move. So SMART was born to hide them. It was spun to give "early" warning. But I have never once seen a SMART alert warn of a drive failure. But plenty proclaim a drive fine that had problems. I have been sysadmin and network admin for more years that I care to admit so have seen plenty of drives (no where as many as backblaze but still enough)
ReplyDeleteRoss - really interesting analysis. I'll see if I can teach myself some R and replicate your work. I'm a geophysicist with a decent maths background so should be able to get into it.
ReplyDeleteQuick question - can the plots be altered so the symbols (+) colour matches the line colour?
it'll be interesting to see how the new 8TB Seagate drives behave. First decent numbers just in and the infant mortality rates are showing promise.
Any chance seeing the K-M analysis including the 2016 data?
DeleteSVG graphs would make this a lot easier to read :|
ReplyDeleteThanks for sharing the article. Keep sharing more with us.
ReplyDeleteHere is something useful for all of you if you are searching for the best place for your home. BLfBhumi providing you the great varieties of Plots near Super Corridor Indore at very affordable rates.
Although I find this article fascinating, from a layman's viewpoint, could someone summarize please? I don't buy drives in vast quantities but as a consumer, I am interested in statistics that would indicate which brand of drive would give me the longest trouble-free lifetime of use.
ReplyDeleteI believe that most consumers have experienced data loss at some point from drive failure (I certainly have) and even after researching anecdotal evidence and forum posts, I'm nowhere closer to knowing concretely (within reason) which drive I should put my faith in... and let's be honest about it, most consumers purchase on price alone, some will decide on performance and/or features. Many simply go with review recommendations which are vague at best so I say "faith" as in you're rolling the dice when you buy as opposed to making an informed decision.
It seems from this analysis that Seagate tends to have a significantly higher failure rate than HGST, am I correct in this?
Thank you for your time and thanks to the author for the fascinating analysis.
Depending on your data size of course you would be best served in using a centralized storage device (yes a NAS) with at least 2 drives mirrored or 4 or more drives in a RAID6.
DeleteGo with the most reliable drives (being the 4TB HGST or the HGST branded as Toshiba) and the NAS replicating to the cloud (Dropbox is my recommendation).
As many before me have noted - buying one drive is luck but if you buy 100 drives then a knowledge of statistics is your friend!
Awesome examination of their data!
ReplyDeleteThanks for posting it!
Bruno (and other laymen) -
ReplyDeleteIf there was a hard drive in the chart that had ZERO failures, then it would be easy to spot which brand/model to purchase in order to get the longest possible life. However, since a hard drive is a complex electro-mechanical component, you could purchase the best performing hard drive on the chart, and experience a failure the day it's installed, and that failure could either be mechanical or electrical, or even logical.
The best you can do is purchase a hard drive that will meet your anticipated storage needs for the long haul, not necessarily the largest hard drive since those are usually fairly new to market and not fully field tested, and make sure that it comes with the longest warranty that you can afford, AND BACKUP your hard drive OFTEN. Enterprise hard drives tend to have the longest warranty and the highest price.
In defense of Seagate, we have found that their "Enterprise-level hard drives" are the most reliable, but we purchase mostly 2TBs and smaller, with the occasional 4TB or 6TB; and Hitachi/HGST runs a close second in reliability.
Don't be fooled into thinking that Solid State Drives/Flash Storage Cards are the answer either, we have found that those fail almost as often as electro-mechanical hard drives. When a Solid State Drive fails, it's also very difficult to recover the data from, if you have not backed it up.
The best answer for whatever type, brand, or model hard drive you purchase is BACKUP OFTEN. A drive can be replaced, your important files, pictures, etc. can't.
Hope this helps!
Tim
CORNICE
Apple Authorized Service Provider
ReplyDeletei really likes your blog and You have shared the whole concept really well. and Very beautifully written,
soulful read! thanks for sharing.
gclub casino
goldenslot casino
goldenslot
Excellent analysis! Obviously a lot of prep and forethought required to produce this high level of reporting.
ReplyDeleteIf someone can do it better, have at it.
Semper vigilis.
State College, Pennsylvania
Solar Eclipse due on August 21.
See MrEclipse.com,
and get your pinhole cameras made well
In advance.
I just read your review and found it very helpful for those who are facing some issues with their hard drives. External hard drives can be the best approach to back up your data on a hard drive that can be connected easily like a USB drive. Well, if you are looking to buy the best one for your data needs then it is recommended to take a look at this list of external hard drives. I bet you will find the best one for your needs on this link.
ReplyDeleteSpot on with this write-up, I truly believe that this amazing site needs much more attention. I’ll probably be returning to read through more, thanks for the information!
ReplyDeletehttp://editorsviews.com/best-scanners-2018/
Is this related to reliability analysis
ReplyDeletethank you.
ReplyDeleteโกลเด้นสล็อต
goldenslot
This comment has been removed by the author.
ReplyDeleteThank You
ReplyDelete.............................
goldenslot
โกลเด้นสล๊อต
สล๊อตออนไลน์
goldenslot
โกลเด้นสล๊อต
สล๊อตออนไลน์
Thank You
ReplyDelete.........
goldenslot
โกลเด้นสล๊อต
สล๊อตออนไลน์
goldenslot
โกลเด้นสล๊อต
สล๊อตออนไลน์
Good
ReplyDelete.................
gclub
gclub casino
จีคลับ
gclub
gclub casino
จีคลับ
thank you
ReplyDelete......................
Mclub
ReplyDeleteThanks for your sharing, it helps me a lot and I think I'll watch your post more.
…………………….
slotxo
สล็อตออนไลน์
ทางเข้า slotxo
Thank you so much for sharing this amazing blog, visit OGEN Infosystem for Website Designing Company in Delhi, India and also for SEO Service in Delhi.
ReplyDeleteWeb Development Company
nice article.
ReplyDeleteSetupsolutions - Alexa | Data Recovery | Garmin
Solve all technical queries here
ReplyDeleteglobalemployees
globalemployees
globalemployees
globalemployees
IOLPOKER Agen Poker Deposit Ovo | Bandar Ceme | DominoQQ
ReplyDeleteDaftar IDN Poker
Agen Togel Deposit Ovo
Bandar Ceme
DominoQQ
the most famous in the Poipet area. We have already looked into the distance so we have been keeping an eye on the website development. Now we have gclub support on mobile and can join in gclub
ReplyDeletecombined score 3-2 to meet the old champions เว็บไซต์ พนันบอล Manchester City at the playoffs. Rivals join Manchester United with 2 goals, 3-2 This game, Dean Smith, the "Leo" promoter, put Emana Wana Samatta in front of the target, with Jack Greelic forming an attack game with Anwar El Ghazi
ReplyDeleteit was very useful information and for that matter I would also like to share one excellent site in order to earn money and for entertainment and relaxation. จีคลับ . slots, card games and whatever your thoughts wish. join in
ReplyDeletehttps://findonfast.com/
ReplyDeleteDogs For Sale in India
https://findonfast.com/
ReplyDeleteNew Old Mobiles For Sale in India
ดูหนังออนไลน์ movie
ReplyDeleteหนังโป๊ไทย
world-class search website like Google บาคาร่าออนไลน์ At the same time, the SBO headquarters also provide
ReplyDeletebuy weed online nevada
ReplyDeleteThis are extremly blogs for everyone.
ReplyDeleteเว็บบาคาร่าขั้นต่ำ เว็บบาคาร่าขั้นต่ำ เว็บบาคาร่าขั้นต่ำ
I like to show my idea about this blog for you.
ReplyDeleteเว็บบาคาร่าขั้นต่ำ เว็บบาคาร่าขั้นต่ำ เว็บบาคาร่าขั้นต่ำ
I love this amazing blogs.
ReplyDeleteเว็บบาคาร่าขั้นต่ำ เว็บบาคาร่าขั้นต่ำ เว็บบาคาร่าขั้นต่ำ เว็บบาคาร่าขั้นต่ำ
Thanks for sharing. สมัคร Gclub
ReplyDeleteสมัคร Gclub
สมัคร Gclub
สมัคร Gclub
This is good info. สมัคร Gclub
ReplyDeleteสมัคร Gclub
สมัคร Gclub
Cool post. สมัคร Gclub
ReplyDeleteสมัคร Gclub
สมัคร Gclub
pussy888 คาสิโนออนไลน์เต็มแบบอย่าง บันเทิงใจแล้วก็เหมาะสมที่สุดในปี 2020
ReplyDeletepussy888 แหล่งพนันออนไลน์ที่ครบวงจรเยอะที่สุดรวมทั้งเยี่ยมที่สุดในตอนนี้ ยินดีให้การอำนวยความสะดวกตลอดการใช้งาน โดยมีแบบอย่างการเล่นพนันที่เป็นเอกลักษณ์ซึ่งไม่ซ้ำใคร มีช้อยส์ตัวเลือกความสนุกสนานให้บริการพร้อม
เหนือชั้นทุกการพนัน เกมส์พนันสูงที่สุดจำเป็นต้องที่ pussy888 เพียงแค่นั้น
การเลือกใช้งานบริการพนันออนไลน์ผ่าน pussy888 ถือได้ว่าอีกหนึ่งปากทางเข้าสู่ความเพลิดเพลินอย่างเต็มรูปแบบ กับการใช้แรงงานพนันเกมส์จำนวนหลายชิ้นสูงที่สุด แม้ว่าจะเป็นเว็บไซต์พนันสมาชิกใหม่ให้บริการได้ไม่นานแม้กระนั้นเรื่องความวิจิตรตระการตาของเกมพนันในรูปแบบต่างๆมีให้ใช้งานครบวงจรเต็มๆทุกแบบอย่าง จากการพัฒนาขึ้นมาเพื่ออยากให้นักการพนันทุกคนเลือกใช้งานร่วมบันเทิงใจได้ไม่ซ้ำ ทำให้เมมเบอร์ทุกคนสามารถร่วมเปิดประสบการณ์พนันออนไลน์ที่ล้ำสมัยได้จากโทรศัพท์เคลื่อนที่ของคุณ และก็ยังเป็นลู่ทางของการเล่นพนันที่พร้อมใช้งานได้ตามสไตล์สิ่งที่มีความต้องการเท่าที่คุณอยากได้ เป็นเสมือนแหล่งพนันที่มีความล้ำยุคเพียงแค่เลือกใช้งานผ่านมือถือสมาร์ทโฟน แท็บเล็ตหรือคอมพิวเตอร์ โน้ตบุค ขอเพียงแต่มีสัญญาณเน็ตก็สามารถช่วยทำให้เข้าถึงการพนันแล้วก็ลุ้นเงินรางวัลได้หลายครั้งเท่าที่คุณปรารถนาแล้ว
จุดเด่นสำหรับเพื่อการใช้บริการเกมคาสิโนออนไลน์ pussy888
สำหรับในการใช้บริการเกมคาสิโนออนไลน์ pussy888 แบบการเล่นพนันออนไลน์ที่เปิดให้บริการเพื่อความเพลิดเพลินอย่างเต็มรูปแบบแล้วก็มีจุดเด่นชอบใจนักเล่นการพนันทุกคนดังต่อไปนี้
สามารถเริ่มของการเล่นพนันได้ด้วยเงินลงทุนอย่างน้อยเพียงแต่ 100 บาทเพียงแค่นั้น ก็เลยเป็นแหล่งพนันออนไลน์ที่เปิดกว้างให้บริการทุกคนได้อย่างยอดเยี่ยม
ผู้คนนักเล่นการพนันมีอิสระของการใช้แรงงานเลือกเล่นพนันได้แบบไม่จำกัด คัดสรรยอดเยี่ยมเกมพนันประสิทธิภาพให้เลือกใช้งานมากมาย
ความสบาย แคล่วคล่องว่องไวตลอดการใช้งานที่ตอบปัญหาได้อย่างยอดเยี่ยม ทำให้การพนันผ่านเว็บไซต์ใช้งานง่ายเพียงแค่มีโทรศัพท์เคลื่อนที่หรือคอมได้ง่ายดายเสียยิ่งกว่าเมื่อก่อนอย่างชัดเจน
มีโปรโมชั่น โบนัส ของขวัญ มอบให้กับสมาชิกทุกท่านไม่จำกัดว่าสมาชิกใหม่หรือสมาชิกเริ่มแรก
หนทางการติดต่อ การใช้แรงงาน ลิงค์ปากทางเข้าอัพเดทให้บริการตลอดในทุกช่วง
เข้ามาร่วมเปิดโลกกว้างที่การเล่นพนันออนไลน์ล้ำสมัยที่สุดที่
pussy888 เป็นแหล่งพนันออนไลน์ที่เปิดให้บริการเพื่อร่วมสนุกสนานกับเกมพนันนานาประการการใช้บริการที่มีแบบล้ำยุค ใครๆก็เลือกร่วมเล่นพนันได้ง่ายไม่ว่าจะเป็นคนใหม่หรือจะอ่อนประสบการณ์หรือผีพนันต่างก็เลือกใช้บริการได้ในทันที เมื่อเลือกใช้บริการกับเว็บไซต์มาตรฐานเชื่อมั่นได้ว่าไม่มีปัญหาหัวข้อการพนันเพราะว่าคณะทำงานพร้อมดูแลความเรียบร้อยแล้วก็ปรับปรุงอย่างไม่อยู่กับที่เพื่อสมาชิกทุกคนไว้วางใจตลอดการใช้งานสูงที่สุด
pussy888 My company has been launched for many years as a company that imports online games that everyone who plays on the world can earn money with my games at any time. No matter where you are
ReplyDeleteIt was an impressive post. I like your post
ReplyDeleteThank you and good luck
I'm waiting for your post. I like your posts, they are fun to read and make them understandable. Compose words and content well. Can be used to tell or spread to people who do not know yet
ReplyDeleteThank you and wish you good luck. บาคาร่า
Feeling good to read such a informative blog, mostly i eagerly search for this kind of blog. I really found your blog informative and unique, waiting for your new blog to read. We offers multipl digital marketing service:
ReplyDeleteDigital marketing Service in Delhi
SMM Services
PPC Services in Delhi
Website Design & Development Packages
SEO Services PackagesLocal SEO services
E-mail marketing services
YouTube plans
Reading this info So i am happy to convey that I’ve a very good uncanny feeling I came upon just what I needed.
ReplyDeleteI such a lot unquestionably will make sure to do not disregard this site
and provides it a glance on a constant basis.
Link Alternatif Layartogel
Link Alternatif Jangkartoto
Link Alternatif Visitogel
Link Alternatif Jalatogel
Thank you very much for providing important information. All your information is very valuable to me.
ReplyDeleteVillage Talkies a top-quality professional corporate video production company in Bangalore and also best explainer video company in Bangalore & animation video makers in Bangalore, Chennai, India & Maryland, Baltimore, USA provides Corporate & Brand films, Promotional, Marketing videos & Training videos, Product demo videos, Employee videos, Product video explainers, eLearning videos, 2d Animation, 3d Animation, Motion Graphics, Whiteboard Explainer videos Client Testimonial Videos, Video Presentation and more for all start-ups, industries, and corporate companies. From scripting to corporate video production services, explainer & 3d, 2d animation video production , our solutions are customized to your budget, timeline, and to meet the company goals and objectives.
As a best video production company in Bangalore, we produce quality and creative videos to our clients.
I really appreciate your support on this.
ReplyDeleteLook forward to hearing from you soon.
I’m happy to answer your questions, if you have any.
คาสิโนออนไลน์
แจกเครดิตฟรี ฝากถอนง่าย
แจกเครดิตฟรี ฝากถอนง่าย
Thank you so much for sharing this amazing blog, the topic is very useful!
ReplyDeleteSANDISK SD6PP4M
In that case, you can still go ahead and try drinking an apple cider vinegar solution. Keep in mind, though, that the results may not always be consistent. All you need to do is make this drink and wait for it to stimulate the fat-burning process, which will soon help you eliminate the THC metabolites content in your body. Furthermore, some people have also attested that directly adding this solution to your urine can do the trick. Clear Choice Incognito Belt Another such device is the Clear Choice Incognito Belt. The belt is quite easy to wear and conceal, and it comes with heat pads to keep the urine at body temperature. Visit: https://www.urineworld.com/
ReplyDeleteThis comment has been removed by the author.
ReplyDeleteBeautiful article shared,we provide mechanical design engineering,product design development,manufacturing support services
ReplyDeletetest bank free download
ReplyDeleteI like viewing web sites which comprehend the price of delivering the excellent useful resource free of charge. I truly adored reading your posting. Thank you!
Đặt vé tại phòng vé Aivivu, tham khảo
ReplyDeletegiá vé máy bay đi Mỹ khứ hồi
vé máy bay từ los angeles về việt nam
vé máy bay từ đức về việt nam giá rẻ
giá vé máy bay nga về việt nam
giá vé máy bay từ anh về việt nam
chuyến bay từ Paris về Hà Nội
vé máy bay tết 2022 Vietjet
nclex review
ReplyDeleteYour good knowledge and kindness in playing with all the pieces was very useful. I don’t know what I would have done if I had not encountered such a step like this
Thanks for the blog very informative and helpful keep it up.
ReplyDeleteUsed Power Supply
Hi there! Nice post! Please tell us when I will see a follow up! BT88
ReplyDeletecasino online
ReplyDeleteThanks for such a great post and the review, I am totally impressed! Keep stuff like this coming.
ฝากต้าบบ✨✨เว็บอื่นแตก ����หรือ ไม่แตก เราไม่รู้
ReplyDelete����แต่เว็บนี้คูณเน้นๆ ����เเตกยับ ฟรีสปินรัวๆ….
ต้องเกมนี้เลย
❤️เอาใจสำหรับใครที่มีทุนน้อย
������สมัครฟรี ������
ฝากไม่มีขั้นต่ำเริ่มต้นแค่ 1บาทเท่านั้น
����คุ้มสุดๆไปเลย
คลิกลี้งนี้ไปเลยจร้า ลิ้งค์รับทรัพย์
คลิกลี้งนี้ไปเลยจร้า แจกเครดิตทุกอาทิตย์7,000
คลิกลี้งนี้ไปเลยจร้า คาสิโนจ่ายดีที่สุด
Clemente Agami Street: JACARANDAS NO. 39, ALAMEDAS DE ZAPOTITLAN, 44720 City: Jalisco State/province/area: Tonalá Phone number 33.3607-0224 Zip code 44720 Country calling code +52 Country México
ReplyDeleteTitanium Max Trimmer - TIKE-TIPS - Home
ReplyDeleteTitanium Max Trimmer. This is the main device which babyliss pro nano titanium straightener works with your phone or tablet as well. You have titanium money clip several devices including Material: black titanium fallout 76 SyntheticItem dimensions: 1.2 x 1.2 titanium apple watch x 1.3 inchesWeight: 1.4 oz Rating: 4 · 6 reviews · men\'s titanium wedding bands $5.95 · In stock
Your article is well-written and understandable even to a novice. As a result, beginners may find it incredibly useful. Thank you very much for sharing that information with us. Writers like you inspire me and I admire and respect them.
ReplyDeletesdcz450 128g a46
IRISH FAKE DRIVING LICENCEI was very impressed by this post, this site has always been pleasant news Thank you very much for such an interesting post, and I meet them more often then I visited this site.
ReplyDeleteThanks for the blog very nice keep going.
ReplyDeletesamsung s9 battery replacement uk
pragmatic play
ReplyDeleteFirst You got a great blog .I will be interested in more similar topics. i see you got really very useful topics , i will be always checking your blog thanks.
slot138
ReplyDeleteExcellent read, Positive site, where did u come up with the information on this posting?I have read a few of the articles on your website now, and I really like your style. Thanks a million and please keep up the effective work.
smm panel
ReplyDeleteSmm Panel
iş ilanları
instagram takipçi satın al
Hirdavatci Burada
beyazesyateknikservisi.com.tr
Servis
TİKTOK JETON HİLESİ
pendik daikin klima servisi
ReplyDeletekadıköy bosch klima servisi
maltepe arçelik klima servisi
çekmeköy daikin klima servisi
maltepe toshiba klima servisi
kadıköy toshiba klima servisi
maltepe beko klima servisi
kadıköy beko klima servisi
kartal lg klima servisi
Meta777
ReplyDeleteLink Meta777Bandar Togel Online
PREDIKSI TOGEL META777Meta777Meta777
Meta777
ReplyDeleteLink Meta777Bandar Togel Online
PREDIKSI TOGEL META777Meta777Meta777
Meta777
Meta777
link Meta777
link Meta777
Link Alternatif Meta777
Link Alternatif Meta777
Meta777
Your article is well written and simple to understand. You make excellent points. Thanks you sharing great blog...
ReplyDeleteI really love the theme on your website, I run a web site , and i would adore to use this theme. Is it a free style, or is it custom? imr 4320 load data
ReplyDeleteLivPure is a nutritional supplement made to enhance liver health and promote weight loss. The liver purification complex and liver fat-burning complex are two complex blends of its natural constituents that have been scientifically backed.
ReplyDeleteLiv Pure is an all-new dietary supplement that was just released recently for the purpose of promoting weight loss. It is a combination of herbal mixes that research has proven to speed up the body's metabolic process in humans. Liv Pure not only aids in weight loss, but it also cleanses the human body of toxins and waste products, boosts general health, and promotes rejuvenation
ReplyDeleteLiv Pure is a ground-breaking dietary supplement for weight loss that targets the root causes of weight gain and obesity. More than 200,000 people have used LivPure's all-natural approach to lose excess body fat without any negative side effects..
ReplyDeleteProDentim is a natural probiotic supplement meant to protect the health of youra teeth and gums.It contains 3.5 billion different probiotic strains that are beneficial to our teeth and has been clinically tested and proven.
ReplyDeleteIkaria Lean Belly Juice is a dietary supplement that addresses obesity by changing the metabolism of the body. Ikaria Lean Belly Juice targets the fundamental causes of obesity and aids the body in shedding weight by overcoming these challenges.
ReplyDeleteA natural and scientifically proven formula that is 100% safe and Ready to Use. It works on weight loss and faster the Oxidation
ReplyDeleteMetabo Flex is an effective weight loss supplement that boosts Metabolism and reduces weight. Metabo Flex is made with 100% All-Natural ingredients that have been clinically proven in reducing weight loss. Metabo Flex improves cognitive performance, and sleep and supports healthy cholesterol.
ReplyDelete"This Is The Best Site For Gmail Service.
ReplyDeleteMore Information Visit Here
Buy Google 5 Star Reviews"
Designed with moisture-wicking fabrics and breathable mesh panels, Essentials Shorts keep you cool and dry, even during intense exercise sessions
ReplyDelete"The consideration to detail in Corteiz pieces is unmatched!"
ReplyDelete"I had an amazing experience! Took my phone in for a screen replacement, and it was fixed in no time. The staff was super helpful, and the price was right. Definitely coming back if I need any other repairs."
ReplyDelete